Back in March, I wrote a post about a new rule discovery algorithm I’d come up with, based on the BLAST bioinformatics algorithm. I’m still hacking on that; it’s gradually meandering towards production status, as time permits, so here’s an update on that progress.
There have been various tweaks to improve memory efficiency; I won’t go into those here, since they’re all in SVN history anyway. But the results are that the algorithm can now extract rules from 3500 spam and 50000 ham messages without consuming more than 36 MB of RAM, or hitting disk. It can also now generate a SpamAssassin rules file directly, and apply a basic set of QA parameters (required hit rate, required length of pattern, etc.).
On top of this, I’ve come up with a workflow to automatically generate a usable batch of rules, on a daily basis, from a spam and ham corpus. This works as follows:
Take a sample of the past 4 days traffic from our spamtrap network. Today this was about 3000 messages.
add the hand-vetted spam from my own accounts over the same period (this helps reduce bias, since spamtraps tend to collect a certain type of spam), about 3400 messages.
discard spams that scored over 10 points (to concentrate on the stuff we’re missing).
Pass the remaining 3517 spams, and text strings from over 50000 nonspam messages, into the “seek-phrases-in-log” script, specifying a minimum pattern length of 30 characters, and a minimum hitrate of 1% (in today’s corpus, a rule would have to hit at least 34 messages to qualify).
That script gronks for a couple of minutes, then produces an output rules file, in this case containing 28 rules, for human vetting. (Since I’ve started this workflow, I’ve only had to remove a couple of rules at this step, and not for false positives; instead, they were leaking spamtrap addresses.)
Once I’ve vetted it, I check it into rulesrc/sandbox/jm/20_sought.cf for testing by the SpamAssassin rule QA system.
The QA results for the ruleset from yesterday (Aug 3) can be seen here, and give a pretty good idea of how these rules have been performing over the past week or two; out of the nearly 70000 messages hit by the rules, only 2 ham mails are hit — 0.0009%.
In fact, I measured the ruleset’s overall performance in the logs provided by the 4 mass-check contributors who provided up-to-date data in yesterday’s nightly mass-check; bb-jm, jm, daf, dos, and theo (all SpamAssassin committers):
| Contributor | Hits | Spams | Percent |
|---|---|---|---|
| bb-jm | 4249 | 24996 | 17.00% |
| jm | 3450 | 14994 | 23.00% |
| daf | 1236 | 35563 | 3.48% |
| dos | 32867 | 100223 | 32.79% |
| theo | 28077 | 382562 | 7.34% |
(bb-jm and jm are both me; they scan different subsets of my mail.)
The “Percent” column measures the percentage of their spam collection that is hit by at least one of these rules; it works out to an average of 16.72% across all contributors. This is underestimating the true hitrate on “fresh” spam, too, since the mass-check corpora also include some really old spam collections (daf’s collection, for example, looks like it hasn’t been updated since the start of July).
Even better, a look at the score-map for these rules shows that they are, indeed, hitting the low-scoring spam that other rules don’t hit.
That’s pretty good going for an entirely-automated ruleset!
The next step is to come up with scores, and publish these for end-user use. I haven’t figured out how this’ll work yet; possibly we could even put them into the default “sa-update” channel, although the automated nature of these rules may mean this isn’t a goer.
If you’re interested, the hits-over-time graph for one of the rules (body JM_SEEK_ICZPZW / Home Networking For Dummies 3rd Edition \$10 /) can be viewed here.
3 Comments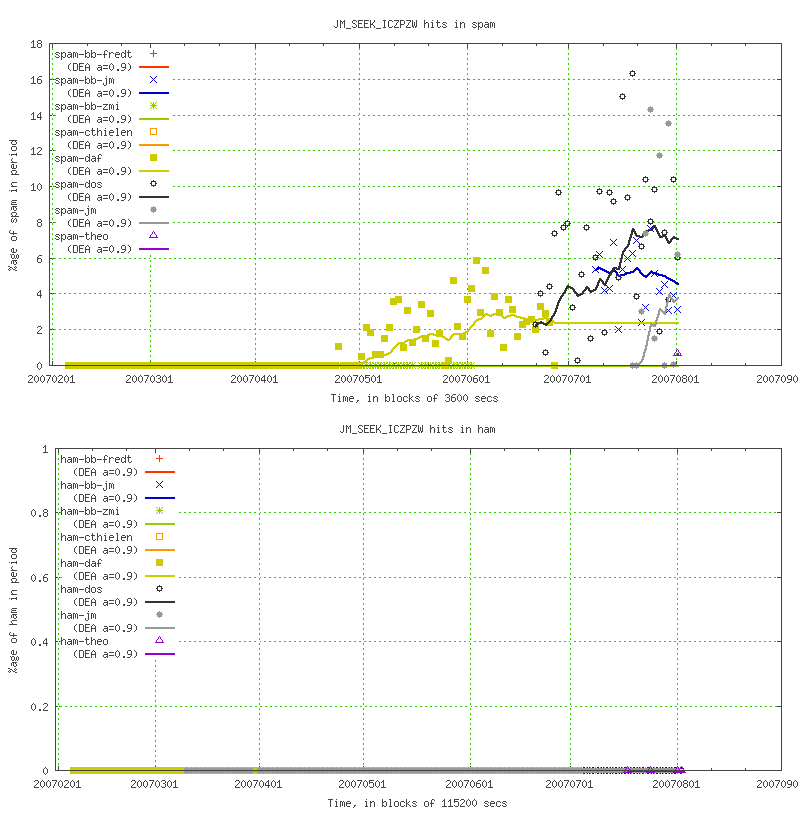{kind=link}