A couple of weeks ago, WebSense posted this article with details of a spammer’s attack on Google’s CAPTCHA puzzle, using web services running on two centralized servers:
[…] It is observed that two separate hosts active on same domain are contacted during the entire process. These two hosts work collaboratively during the CAPTCHA break process. […]
Why [use 2 hosts]? Because of variations included in the Google CAPTCHA image, chances are that host 1 may fail breaking the code. Hence, the spammers have a backup or second CAPTCHA-learning host 2 that tries to learn and break the CAPTCHA code. However, it is possible that spammers also use these two hosts to check the efficiency and accuracy of both hosts involved in breaking one CAPTCHA code at a time, with the ultimate goal of having a successful CAPTCHA breaking process.
To be specific, host 1 has a similar concept that was used to attack Live mail CAPTCHA. This involved extracting an image from a victim’s machine in the form of a bitmap file, bearing BM.. file headers and breaking the code. Host 2 uses an entirely different concept wherein the CAPTCHA image is broken into segments and then sent as a portable image / graphic file bearing PV..X file headers as requests. […]
While it doesn’t say as such, some have read the post to mean that Google’s CAPTCHA has been solved algorithmically. I’m pretty sure this isn’t the case. Here’s why.
Firstly, the FAQ text that appears on “host 1” (thanks Alex for the improved translation!):
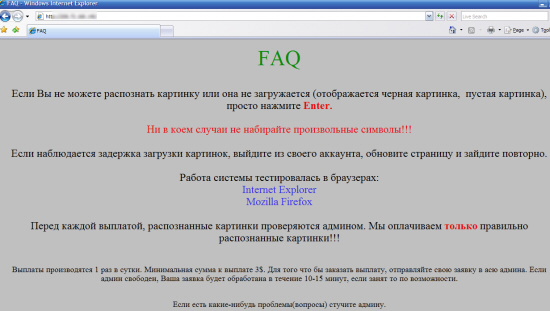
FAQ
If you cannot recognize the image or if it doesn’t load (a black or empty image gets displayed), just press Enter.
Whatever happens, do not enter random characters!!!
If there is a delay in loading images, exit from your account, refresh the page, and log in again.
The system was tested in the following browsers: Internet Explorer Mozilla Firefox
Before each payment, recognized images are checked by the admin. We pay only for correctly recognized images!!!
Payment is made once per 24 hours. The minimum payment amount is $3. To request payment, send your request to the admin by ICQ. If the admin is free, your request will be processed within 10-15 minutes, and if he is busy, it will be processed as soon as possible.
If you have any problems (questions), ICQ the admin.
That reads to me a lot like instructions to human “CAPTCHA farmers”, working as a distributed team via a web interface.
Secondly, take a look at the timestamps in this packet trace:

The interesting point is that there’s a 40-second gap between the invocation on “Captcha breaking host 1” and the invocation on “Captcha breaking host 2”. There is then a short gap of 5 seconds before the invocations occur on the Gmail websites.
Here’s my theory: “host 1” is a web service gateway, proxying for a farm of human CAPTCHA solvers. “host 2”, however, is an algorithm-driven server, with no humans involved. A human may take 40 seconds to solve a CAPTCHA, but pure code should be a lot speedier.
Interesting to note that they’re running both systems in parallel, on the same data. By doing this, the attackers can
collect training data for a machine-learning algorithm (this is implied by the ‘do not enter random characters!’ warning from the FAQ — they don’t want useless training data)
collect test cases for test-driven development of improvements to the algorithm
measure success/failure rates of their algorithms, “live”, as the attack progresses
Worth noting this, too:
Observation*: On average, only 1 in every 5 CAPTCHA breaking requests are successfully including both algorithms used by the bot, approximating a success rate of 20%. The second algorithm (segmentation) has very poor performance that sometimes totally fails and returns garbage or incorrect answers.
So their algorithm is unreliable, and hasn’t yet caught up with the human farmers. Good news for Google — and for the CAPTCHA farmers of Romania ;)
Update: here’s the NYTimes’ take, with broadly agreeing comments from Brad Taylor of Google. (The Register coverage is off-base, however.)